Mẫu Chương trình Cập nhật Tin tức
Cập nhật lần cuối:
Thảo luậnMục lục
Sử dụng qua Dòng Lệnh (CLI)
Sau khi hoàn tất cài đặt cấu hình thư viện, bạn có thể khởi chạy chương trình theo dõi tin tức trực tiếp từ dòng lệnh Terminal nhằm kiểm thử quá trình trích xuất và lưu trữ dữ liệu:
vnstock-news-crawlerBởi vì vnstock_news sở hữu danh mục tính năng đa dạng, bạn có thể giao phó quy trình kiến trúc mã nguồn (coding) cho AI để có thể tập trung vào các logic nghiệp vụ thay vì kỹ thuật. Tải tài liệu theo liên kết Agent Guide bên dưới và mở trong các chương trình chuyên biệt như Google Antigravity, Claude Code đẻ tác nhân AI sử dụng kỹ năng được Vnstock chỉ dẫn và tiến hành xây dựng kịch bản chuyên sâu theo mức độ tùy chỉnh cao.
 Khởi động chương trình Vnstock News từ Terminal của macOS
Khởi động chương trình Vnstock News từ Terminal của macOS
Khi khởi chạy, chương trình quản lý luồng điều phối (Orchestrator) tự động kết nối nguồn tin công khai của các báo được thiết kế cho bot truy cập, thực hiện trích xuất đồng lịch sử tin tức theo điều kiện thời gian bạn yêu cầu và biên dịch tập tin dưới dạng CSV, lưu trữ tại thư mục định danh output.
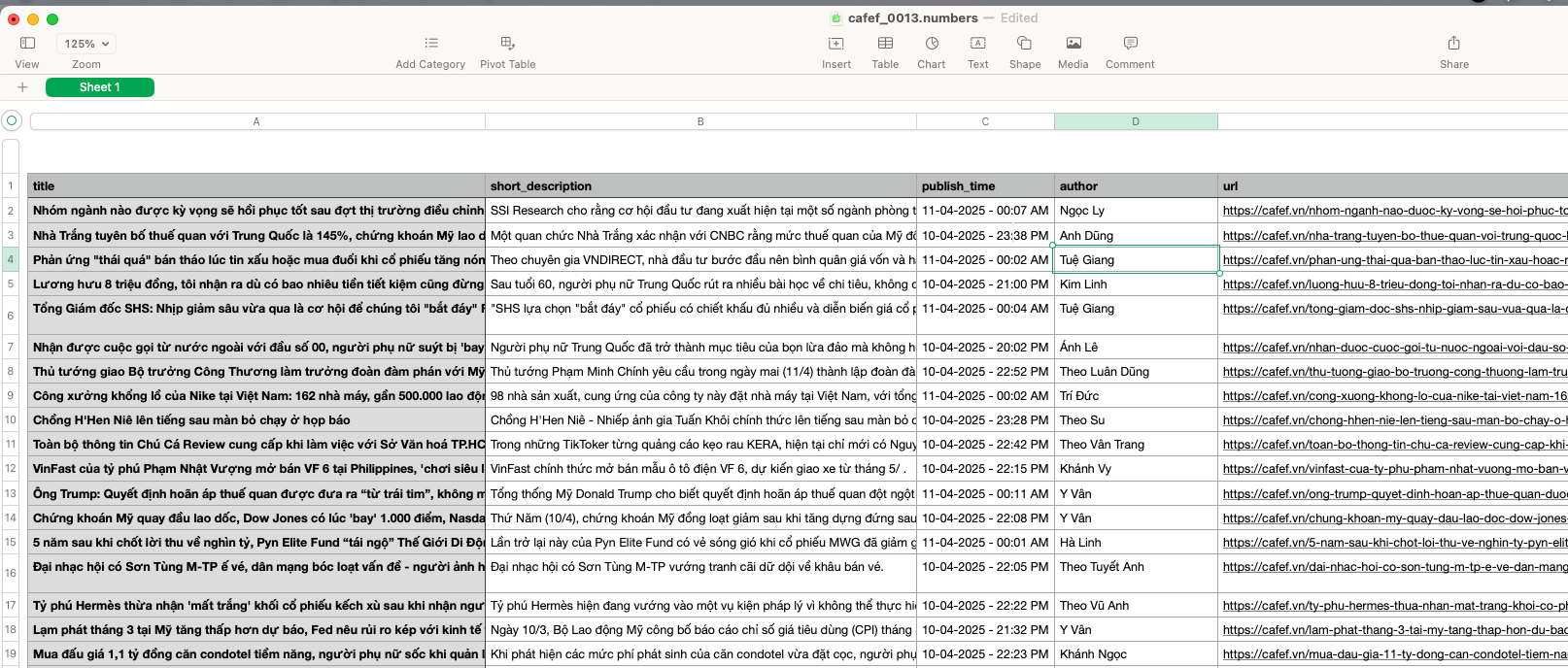 Nội dung dữ liệu tin tức được chuẩn hoá từ Vnstock News
Nội dung dữ liệu tin tức được chuẩn hoá từ Vnstock News
Khung báo cáo sau thống kê sẽ xuất về tệp tĩnh mang thuật ngữ news_summary.txt:
News Monitor Report - 2024-xx-xx
==================================================
STATISTICS
--------------------------------------------------
Total articles collected: 580
TRENDING TOPICS
--------------------------------------------------
1. chứng khoán: 107 mentions
2. thị trường: 76 mentions
...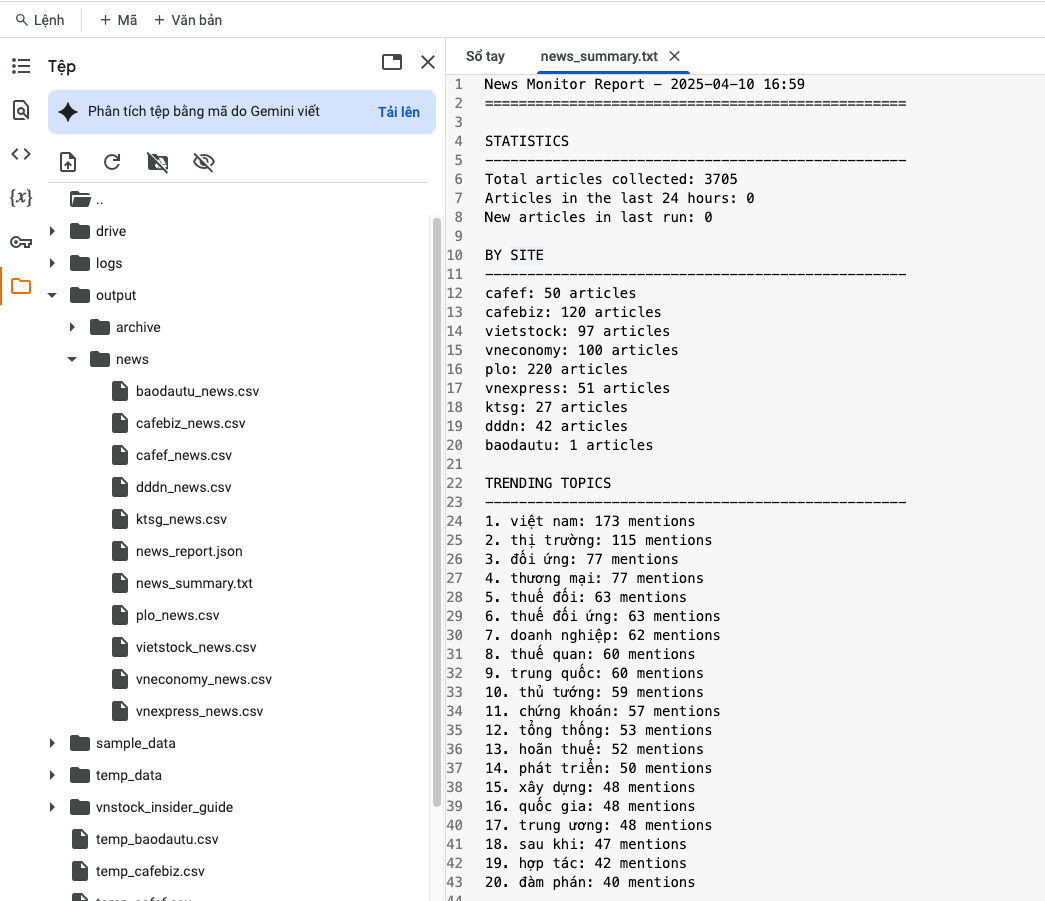 Tóm tắt kết quả chương trình khi kết nối và phân tích tin tức trên Google Colab
Tóm tắt kết quả chương trình khi kết nối và phân tích tin tức trên Google Colab
Tham khảo hệ thống giám sát bằng kịch bản Python
Với mục đích tham khảo cấu trúc, đoạn mã Python theo tiêu chuẩn dưới đây triển khai khai thác nguồn tin nóng (RSS) cũng như cào lưu trữ tuần tự (Sitemap) từ các nhà cung cấp tin. Trong quá trình tạo dự án, bạn hoàn toàn có thể yêu cầu AI Agent xây dựng hệ thống thay vì tự vận hành mã thủ công:
from vnstock_news.api.enhanced import EnhancedNewsCrawler
import asyncio
async def automated_news_harvester():
print("Khởi động quy trình thu thập nội dung cấu trúc hóa...")
# Sử dụng EnhancedNewsCrawler tích hợp sẵn Caching và Cleaning
crawler = EnhancedNewsCrawler(cache_enabled=True)
print("\\n[1] Lấy danh mục tin từ hệ thống máy chủ sitemap của CafeF")
# Trích xuất dữ liệu bất đồng bộ với hiệu suất cao
historical_corpus = await crawler.fetch_articles_async(
sources=["https://cafef.vn/latest-news-sitemap.xml"],
top_n=50,
clean_content=True
)
if not historical_corpus.empty:
print(f"Trích xuất {len(historical_corpus)} văn bản thành công.")
# Kết xuất CSV
filename = "cafef_audit_latest.csv"
historical_corpus.to_csv(filename, index=False)
print(f"\\nHoàn thành kết xuất dữ liệu cấu trúc về đường dẫn: {filename}")
if __name__ == "__main__":
asyncio.run(automated_news_harvester())Những lệnh truyền dẫn qua class BatchCrawler mang lại độ kiểm soát bảo trì đáng kể thay vì vận động thao tác mã ngẫu nhiên trên các thư viện HTTP Requests ở cấp độ mạng.
Thảo luận