
Dữ liệu khớp lệnh tick data chứng khoán & ứng dụng thực tế
Mục lục
Nếu bạn thường xuyên theo dõi thị trường chứng khoán, chắc hẳn bạn đã quen với "Bảng giá" hay mục "Lịch sử khớp lệnh" (tick data) trên giao diện các website của công ty chứng khoán. Trong giờ giao dịch, khu vực này hiển thị những con số xanh, đỏ nhảy múa liên tục: giá, khối lượng, lệnh mua, lệnh bán...
Đó chính là dữ liệu trong phiên khớp lệnh liên tục1. Tuy nhiên, việc chỉ nhìn những con số thay đổi trên màn hình khi bạn theo dõi một cổ phiếu cụ thể ngoài việc cho bạn cảm giác hưng phấn hoặc FOMO2 thì còn ý nghĩa gì khác không?
Những chuyên gia giàu kinh nghiệm có thể "đọc vị" thị trường nhanh chóng, nhưng họ đã phải đánh đổi bằng rất nhiều năm rèn luyện và học phí trên thị trường. May mắn là, bạn hoàn toàn có thể rút ngắn quá trình đó và tránh được những rủi ro không đáng có bằng cách tiếp cận bài bản theo góc nhìn của một nhà phân tích dữ liệu.
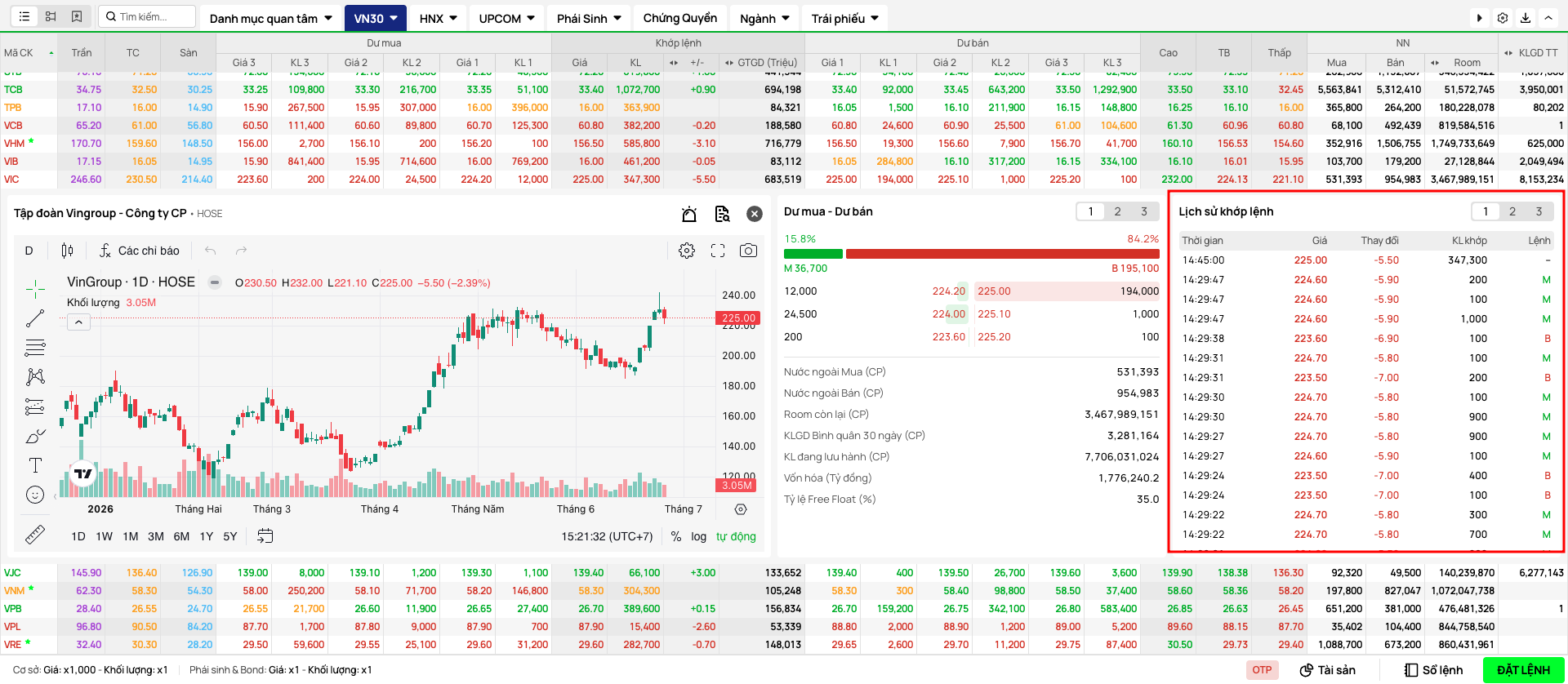 Giao diện website chứng khoán thể hiện dữ liệu khớp lệnh
Giao diện website chứng khoán thể hiện dữ liệu khớp lệnh
Trong bài viết này thuộc chuỗi chia sẻ kiến thức nền tảng về dữ liệu3, chúng ta sẽ cùng "giải ngố" xem bản chất thực sự của dữ liệu khớp lệnh là gì, hiểu lầm phổ biến nhất khi tải dữ liệu này về phân tích, và cách người ta sử dụng nó để quan sát các dòng tiền hoạt động ra sao trong phiên.
1. Dữ liệu khớp lệnh là gì?
Dữ liệu khớp lệnh (tick data) ghi nhận chi tiết từng giao dịch đơn lẻ diễn ra trên thị trường, chính xác đến từng giây. Nó ghi lại: Thời điểm khớp lệnh, Mức giá, Khối lượng và Phe chủ động4.
Một đặc tính quan trọng của dữ liệu này là nó phụ thuộc chặt chẽ vào thời gian giao dịch thực tế của từng thị trường. Ví dụ, đối với chứng khoán phái sinh (Hợp đồng tương lai), phiên giao dịch bắt đầu từ 09:00, trong khi chứng khoán cơ sở bắt đầu vào 09:15. Cả hai thị trường đều kết thúc đợt khớp lệnh định kỳ đóng cửa (ATC) vào lúc 14:45. Hiểu biết cơ bản này giúp bạn xác định được tập dữ liệu tick data mình đã tải về đã trọn vẹn phiên giao dịch hay chưa để tăng giới hạn số bản ghi cần tải về.
Trong khi biểu đồ nến5 mà chúng ta hay xem đã "nén" dữ liệu lại theo từng khoảng thời gian (ví dụ: nến 1 phút, nến 1 ngày), thì dữ liệu khớp lệnh chính là những "viên gạch" nhỏ nhất xây nên cây nến đó.
Hiểu đơn giản: Biểu đồ nến cho bạn biết kết quả trong một khung thời gian giao dịch, còn dữ liệu khớp lệnh cho bạn xem lại toàn bộ diễn biến của cuộc giằng co giữa phe mua và phe bán trong khung thời gian đó. Một nguyên tắc cơ bản là: Tổng khối lượng của tất cả các lệnh khớp trong khung thời gian đó cộng lại phải bằng chính xác khối lượng tổng hiển thị trên cây nến khung thời gian đó.
2. Hiểu lầm thường gặp với dữ liệu khớp lệnh: "Dữ liệu bị lỗi trùng lặp"
Rất nhiều nhà đầu tư khi bắt đầu tìm tòi, tải lịch sử giao dịch về file Excel (hoặc dùng Python để lấy dữ liệu) thường bối rối khi thấy: Tại cùng một giây (ví dụ 14:29:23), có tới hàng chục dòng dữ liệu giống hệt nhau y đúc về mức giá và thời gian. Phải chăng đây là dữ liệu trùng lặp cần loại bỏ6 như sách dạy phân tích dữ liệu từng nói?
Phản xạ tự nhiên của nhiều người là: "Chắc hệ thống bị lỗi lặp dữ liệu rồi", và tìm cách filter xóa bớt đi cho gọn. Đây là một hiểu lầm làm mất đi giá trị quan trọng của dữ liệu.
Thực tế không có lỗi hệ thống nào ở đây cả. Hãy tưởng tượng:
- Trên thị trường đang có 50 người đặt lệnh Bán chờ sẵn, mỗi người bán 100 cổ phiếu ở giá 20.0 (tổng cộng 5,000 cổ phiếu chờ bán).
- Đột nhiên, một nhà đầu tư lớn quăng một lệnh mua bất chấp giá7 khối lượng 5,000 cổ phiếu.
- Hệ thống của Sở giao dịch trong phiên khớp lệnh liên tục, sẽ lập tức khớp lệnh Mua này với 50 lệnh Bán nhỏ lẻ kia trong cùng một tích tắc.
Kết quả trả về cho bạn là 50 dòng dữ liệu khớp lệnh ở cùng một mức giá, cùng một giây. Nếu bạn gộp hoặc xóa chúng đi vì tưởng là trùng lặp, bạn đã vô tình xóa mất dấu vết của lệnh hợp lệ và làm sai lệch hoàn toàn khối lượng giao dịch thực tế của ngày hôm đó.
3. Từ Tick Data đến OHLCV: Giải mã cấu trúc biểu đồ nến
Như đã đề cập, biểu đồ nến5 thực chất chỉ là một lớp vỏ bọc thống kê được nén lại từ dữ liệu khớp lệnh trong một khoảng thời gian nhất định. Nhìn từ góc độ dữ liệu:
- Open (Giá mở cửa): Chính là mức giá của lệnh khớp sớm nhất xuất hiện trong khung thời gian đó.
- Close (Giá đóng cửa): Mức giá của lệnh khớp muộn nhất (cuối cùng) trước khi khép lại khung thời gian.
- High (Giá cao nhất): Mức giá lớn nhất trong toàn bộ các lệnh khớp của khoảng thời gian đó.
- Low (Giá thấp nhất): Mức giá nhỏ nhất được ghi nhận.
- Volume (Khối lượng): Tổng khối lượng của tất cả các lệnh khớp cộng lại.
Hãy lấy ví dụ từ một đoạn dữ liệu khớp lệnh 1 phút dưới đây (từ 09:15:00 đến 09:15:59):
| Index | time | price | volume | match_type | id |
|---|---|---|---|---|---|
| 3909 | 2026-06-25 09:15:06 | 230.5 | 16500 | ato | 2026-06-25_091506_2305000_16500 |
| 3905 | 2026-06-25 09:15:07 | 232.0 | 200 | Buy | 2026-06-25_091507_2320000_200 |
| 3908 | 2026-06-25 09:15:07 | 230.5 | 500 | Sell | 2026-06-25_091507_2305000_500 |
| 3907 | 2026-06-25 09:15:07 | 232.0 | 200 | Buy | 2026-06-25_091507_2320000_200 |
| 3906 | 2026-06-25 09:15:07 | 230.5 | 300 | Sell | 2026-06-25_091507_2305000_300 |
| 3904 | 2026-06-25 09:15:26 | 232.0 | 100 | Buy | 2026-06-25_091526_2320000_100 |
| 3903 | 2026-06-25 09:15:38 | 232.0 | 100 | Buy | 2026-06-25_091538_2320000_100 |
| 3902 | 2026-06-25 09:15:41 | 230.6 | 100 | Sell | 2026-06-25_091541_2306000_100 |
| 3901 | 2026-06-25 09:15:54 | 230.6 | 500 | Sell | 2026-06-25_091554_2306000_500 |
Nhìn vào dữ liệu trên, ta dễ dàng nhặt ra được các điểm mốc để vẽ nên một cây nến 1 phút hoàn chỉnh:
- Open = 230.5 (lệnh đầu tiên lúc 09:15:06)
- High = 232.0 (các lệnh tại 09:15:07, 09:15:26, 09:15:38)
- Low = 230.5 (nhỏ nhất trong số các mức giá khớp)
- Close = 230.6 (lệnh cuối cùng lúc 09:15:54)
- Volume = 18.500 (tổng cộng tất cả khối lượng)
Trong thực tế, để chuyển đổi hàng ngàn dòng dữ liệu khớp lệnh thành biểu đồ nến (gọi là kỹ thuật lấy mẫu8), các kỹ sư dữ liệu thường sử dụng thư viện Pandas9 trong Python. Dưới đây là cách biến đổi bảng dữ liệu10 gốc thành dữ liệu nến 1 phút nhanh gọn và chuẩn xác:
import pandas as pd
# 1. Chuyển cột 'time' thành kiểu DateTime và đặt làm Index (điều kiện bắt buộc để xử lý chuỗi thời gian)
df['time'] = pd.to_datetime(df['time'])
df.set_index('time', inplace=True)
# 2. Thực hiện Resampling (nhóm dữ liệu) theo khung 1 phút ('1min')
df_ohlcv = df.resample('1min').agg({
'price': ['first', 'max', 'min', 'last'], # Lần lượt tương ứng: Open, High, Low, Close
'volume': 'sum' # Tính tổng Volume
})
# 3. Làm phẳng tên cột cho chuẩn mực
df_ohlcv.columns = ['open', 'high', 'low', 'close', 'volume']
print(df_ohlcv)Vì dữ liệu khớp lệnh là dữ liệu thô chi tiết nhất, nên từ tập dữ liệu này, bạn có thể tự do lấy mẫu ra bất kỳ khung thời gian nào bạn muốn để phục vụ phân tích: từ nến 1 phút (1m), 5 phút (5m), 15 phút (15m), 30 phút (30m), 1 giờ (1H), 4 giờ (4H) hay nến 1 ngày (1D) chỉ bằng cách thay đổi tham số 1min trong hàm trên.
Hiểu được bản chất cấu tạo nến là bước đệm quan trọng, nhưng sức mạnh thực sự của dữ liệu khớp lệnh lại nằm ở khả năng giúp chúng ta bóc tách hành vi sâu xa của thị trường.
4. Ứng dụng thực tế: Bóc tách dòng tiền từ dữ liệu thô
Nếu chỉ nhìn hàng chục ngàn dòng tick data chạy qua mặt mỗi ngày, chúng ta rất khó để rút ra kết luận. Vì vậy, trong phân tích thực tế, người ta dùng các kỹ thuật gom nhóm dữ liệu này lại để tìm ra những góc nhìn sâu sắc hơn11. Mục tiêu là để trả lời câu hỏi: Ai đang thực sự chi phối xu hướng giá hiện tại?
Nhìn xuyên thấu cây nến (Footprint)
Thay vì chỉ biết giá đóng cửa của ngày hôm nay là 20.5, bằng cách nhóm các mức giá từ dữ liệu khớp lệnh, chúng ta có thể vẽ ra một "bản đồ nhiệt" (Volume Profile/Footprint12) xem khối lượng giao dịch thực sự tập trung nhiều nhất ở mức giá nào. Vùng giá có khối lượng khớp nhiều nhất chính là vùng tranh chấp quan trọng, thường trở thành ngưỡng hỗ trợ hoặc kháng cự cứng.
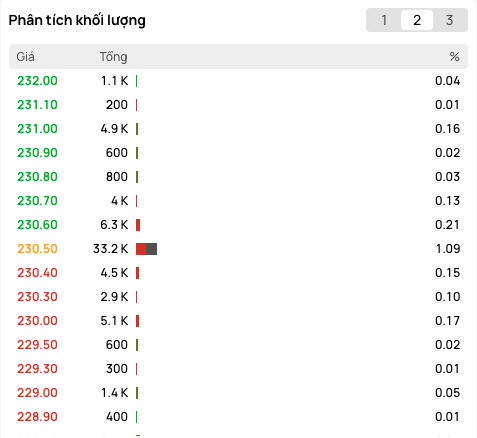 Minh hoạ dữ liệu thể hiện khối lượng khớp lệnh theo bước giá
Minh hoạ dữ liệu thể hiện khối lượng khớp lệnh theo bước giá
Phân loại độ lớn của lệnh (Tay to vs Nhỏ lẻ)
Hình minh hoạ dưới đây là cách phân loại nhà đầu tư theo giá trị lệnh được ứng dụng trên nền tảng của một số công ty chứng khoán. Khi trải nghiệm thực tế trên các website này, nếu rê chuột vào biểu tượng chú thích (tooltip) bên cạnh, bạn sẽ thấy nội dung diễn giải chi tiết cách họ định nghĩa quy mô cho từng nhóm.
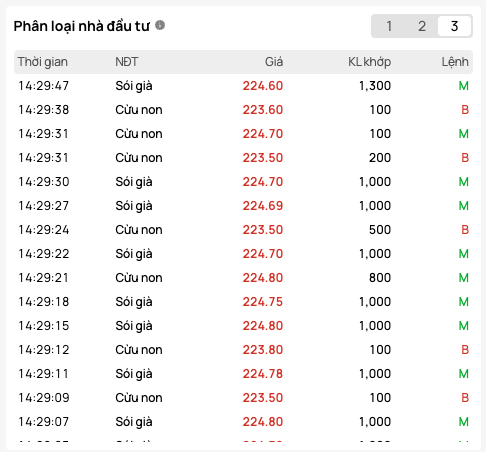 Minh hoạ cách một website phân loại nhà đầu tư theo giá trị khớp lệnh
Minh hoạ cách một website phân loại nhà đầu tư theo giá trị khớp lệnh
Về bản chất, cách phân tích này dựa trên giá trị của từng lệnh đặt (tính bằng công thức: Khối lượng x Giá khớp). Sự phân loại này mang tính tương đối theo logic thông thường về quy mô vốn trên thị trường, từ đó bóc tách dòng tiền thành các nhóm:
- Cừu non (Dòng tiền nhỏ lẻ): Những lệnh có giá trị thấp. Thường đại diện cho tâm lý đám đông nhỏ lẻ, dễ hưng phấn hoặc hoảng loạn.
- Sói già (Nhà đầu tư kinh nghiệm): Những lệnh có giá trị tầm trung, thường đến từ các nhà đầu tư cá nhân dày dạn kinh nghiệm.
- Cá mập (Dòng tiền lớn/Tổ chức): Những lệnh có giá trị cực lớn, dứt khoát quét sạch một mức giá. Đây thường là dấu vết của các quỹ, tổ chức, hay "tay to" đang gom hoặc xả hàng.
 Một website chứng khoán mô tả cách họ gán nhãn phân loại nhà đầu tư theo giá trị lệnh khớp
Một website chứng khoán mô tả cách họ gán nhãn phân loại nhà đầu tư theo giá trị lệnh khớp
Một điểm hạn chế khi xem trên website là bạn phải chấp nhận các mức phân chia cố định do công ty chứng khoán thiết lập sẵn (ví dụ: lệnh dưới 100 triệu, từ 100-500 triệu, trên 1 tỷ...). Nếu bạn chủ động tải tick data thô và dùng Python, bằng các phương pháp phân nhóm13, bạn có thể tự do phân loại dữ liệu theo bất kỳ giá trị lệnh mong muốn nào phù hợp với khẩu vị phân tích của riêng bạn.
Bên cạnh việc nhìn vào xu hướng chung, việc bóc tách riêng nhóm lệnh "Cá mập" còn mở ra một góc nhìn lợi hại khác: Tính toán giá bình quân của dòng tiền lớn. Hãy hình dung một quỹ đầu tư muốn mua gom hàng triệu cổ phiếu; họ hiếm khi mua hết trong một phiên duy nhất mà phải chia nhỏ ra gom dần ở nhiều mức giá trong suốt nhiều phiên để tránh làm giá tăng sốc. Bằng cách lọc ra toàn bộ các lệnh mua chủ động quy mô lớn này và tính mức giá trung bình của chúng, bạn có thể lờ mờ xác định được vùng "giá vốn" của tay to trong ngày hay một khoảng thời gian. Vùng giá này thường tạo ra những ngưỡng hỗ trợ hoặc kháng cự tâm lý rất uy tín.
Ví dụ: Khi biểu đồ giá đang tăng vọt và có vẻ rất tích cực, nhưng dữ liệu khớp lệnh bóc tách ra lại cho thấy phe "Cá mập" toàn tung ra lệnh chủ động Bán (kéo xả), nhà đầu tư sẽ có thêm cơ sở để thận trọng hơn thay vì FOMO mua đuổi theo tâm lý chung.
5. Xử lý dữ liệu khớp lệnh như thế nào?
Việc xử lý hàng chục nghìn dòng dữ liệu khớp lệnh mỗi ngày không phải là cách lý tưởng để dùng Excel vì tốn thời gian và không thuận tiện. Trong thực tế, các hệ thống phân tích dữ liệu tự động hoặc các công cụ nguồn mở như Vnstock Python sinh ra để giúp công đoạn này trở nên nhẹ nhàng hơn.
Chỉ với 3 dòng lệnh Python, bạn có thể tự động lấy toàn bộ lịch sử khớp lệnh trong ngày của một cổ phiếu để phục vụ cho các ý tưởng phân tích của riêng mình, thay vì phải copy/paste thủ công từ các trang web.
Ví dụ: Sử dụng thư viện
vnstock_datađể tải dữ liệu khớp lệnh trong ngày của mã Hợp đồng tương lai VN30F1M (hoặc bạn có thể thay bằng mã cổ phiếu cơ sở như VIC).
from vnstock_data import Market
# Kết nối lấy luồng dữ liệu khớp lệnh liên tục của mã VN30F1M
# Dữ liệu trả về tự động được cấu trúc gọn gàng: thời gian (time), giá (price), khối lượng (volume), loại lệnh (match_type: Mua/Bán chủ động)
df_intraday = Market().equity("VN30F1M").intraday(limit=50_000)
df_intradayKết quả trả về sẽ có dạng như sau:
time price volume match_type id
0 2026-06-25 14:45:01 2006.4 3790 Unknown 2026-06-25_144501_20064_3790
1 2026-06-25 14:30:00 2006.1 7 Buy 2026-06-25_143000_20061_7
2 2026-06-25 14:30:00 2006.4 3 Buy 2026-06-25_143000_20064_3
3 2026-06-25 14:30:00 2005.9 1 Sell 2026-06-25_143000_20059_1
4 2026-06-25 14:29:59 2006.1 2 Sell 2026-06-25_142959_20061_2
... ... ... ... ... ...
27153 2026-06-25 09:00:01 2009.0 4 Buy 2026-06-25_090001_20090_4
27154 2026-06-25 09:00:01 2008.8 1 Sell 2026-06-25_090001_20088_1
27155 2026-06-25 09:00:00 2009.0 18 Buy 2026-06-25_090000_20090_18
27156 2026-06-25 09:00:00 2008.9 32 Buy 2026-06-25_090000_20089_32
27157 2026-06-25 09:00:00 2008.8 1453 Unknown 2026-06-25_090000_20088_1453
[27158 rows x 5 columns]Bạn có thể thấy toàn bộ 27.158 lệnh khớp trong ngày được trả về chi tiết đến từng giây. Lưu ý rằng giai đoạn thị trường tháng 6/2026 có số lượng giao dịch không sôi động như các tháng đầu năm. Có những thời điểm thanh khoản bùng nổ, tổng số giao dịch có thể gấp đôi, gấp ba con số này là hoàn toàn bình thường (ngay cả mã cổ phiếu lớn như VIC thời điểm cuối ngày 25/6/2026 cũng chỉ có chưa tới 4.000 lệnh khớp trong phiên liên tục theo thống kê, trong khi những tháng sôi động trước đó con số này có thể vượt trên 50.000 lệnh mỗi phiên).
Thông thường trên giao diện xem của website, loại dữ liệu này chỉ được tải mỗi 100 dòng và bạn phải cuộn trang liên tục để xem, không có sẵn nút tải về. Đó là lý do vì sao các công cụ lập trình Python như Vnstock có thể mở ra những cơ hội mới để nhà đầu tư tự do phân tích dữ liệu chuyên sâu, thay vì chỉ lướt nhanh qua bảng điện như một vị khách qua đường.
Thử thách: Ghép nối dữ liệu trong phiên
Một trong những thử thách lớn nhất của các bạn đang làm quen với phương pháp vibe coding và xử lý dữ liệu là vấn đề ghép nối dữ liệu. Trong thực tế, dữ liệu tải về từ các API thường là dữ liệu cộng dồn. Dù bạn có thể dùng một số tham số phân trang (paging) hoặc lọc theo ID, nhưng không phải nguồn dữ liệu nào cũng hỗ trợ chức năng này. Cách phổ biến nhất là mỗi lần gọi API, hệ thống sẽ trả về toàn bộ dữ liệu có sẵn tính đến thời điểm hiện tại.
Nếu bạn lập trình một chương trình cứ mỗi phút lại gọi API một lần và nhắm mắt dùng lệnh append (nối tiếp) dữ liệu mới vào dữ liệu cũ, bạn sẽ tạo ra hàng vạn dòng trùng lặp vô phương cứu chữa (vì có thể có hàng chục lệnh khớp trong cùng một giây như đã phân tích ở phần 2). Để giải quyết bài toán này, kỹ thuật chuẩn xác nhất là cắt dữ liệu đến mốc thời gian làm tròn phút.
Hãy hình dung: Tại thời điểm 10:01, chương trình của bạn chạy tự động để tải về một tập dữ liệu mới. Để ghép nối nó một cách hoàn hảo vào tập dữ liệu cũ (lấy lúc 10:00), bạn cần:
- Xác định mốc thời gian làm tròn phút gần nhất ở quá khứ, ví dụ
10:00:59. - Ở tập dữ liệu cũ: Xóa toàn bộ các lệnh xuất hiện sau
10:00:59. - Ở tập dữ liệu mới vừa tải về: Xóa toàn bộ các lệnh xuất hiện trước và bằng
10:00:59. - Cuối cùng, nối tập dữ liệu mới (đã gọt dũa) vào tập dữ liệu cũ.
Kỹ thuật này đảm bảo dữ liệu khớp lệnh của bạn được nối dài liên tục, mượt mà, hoàn toàn không bị lặp hay thiếu sót bất kỳ một tick nào!
Dưới đây là đoạn mã Python mô phỏng logic cắt ghép này bằng thư viện Pandas:
import pandas as pd
def merge_intraday_data(df_old, df_new, cutoff_time):
"""
Hàm ghép nối dữ liệu khớp lệnh liên tục tránh trùng lặp
- cutoff_time: Mốc thời gian làm tròn (ví dụ: '2026-06-25 10:00:59')
"""
# Đảm bảo cột 'time' ở đúng định dạng datetime
df_old['time'] = pd.to_datetime(df_old['time'])
df_new['time'] = pd.to_datetime(df_new['time'])
# Bước 1: Tập dữ liệu cũ - Giữ lại các lệnh khớp TRƯỚC và BẰNG mốc thời gian
df_old_clean = df_old[df_old['time'] <= cutoff_time]
# Bước 2: Tập dữ liệu mới - Giữ lại các lệnh khớp SAU mốc thời gian
df_new_clean = df_new[df_new['time'] > cutoff_time]
# Bước 3: Nối 2 tập dữ liệu lại với nhau một cách hoàn hảo
df_merged = pd.concat([df_old_clean, df_new_clean], ignore_index=True)
return df_mergedLời kết
Việc hiểu đúng bản chất của dữ liệu khớp lệnh giúp chúng ta chuyển từ việc nhìn bảng điện một cách cảm tính sang việc có cơ sở dữ liệu vững chắc hơn. Đằng sau những con số nhảy múa tưởng chừng khô khan luôn ẩn chứa câu chuyện về hành vi và dòng tiền thực tế của các bên tham gia thị trường.
Tất nhiên, dữ liệu thô chỉ là nguyên liệu. Cách chúng ta chế biến và diễn dịch chúng kết hợp với các phương pháp phân tích khác mới tạo ra sự khác biệt. Hi vọng bài viết này đã giúp bạn có thêm một góc nhìn thực tế và rõ ràng hơn về dữ liệu Intraday.
Trong các bài viết tiếp theo, chúng ta sẽ tiếp tục "giải mã" những khái niệm thú vị khác dưới góc nhìn phân tích dữ liệu và hệ thống. Hãy tiếp tục theo dõi và lan toả bài viết đến những người trong vòng kết nối của bạn.
Footnotes
-
Dữ liệu khớp lệnh liên tục (Tick-by-tick / Intraday data): Dữ liệu ghi nhận chi tiết từng giao dịch đơn lẻ diễn ra trên thị trường, chính xác đến từng giây hoặc mili-giây. ↩
-
FOMO (Fear Of Missing Out): Hội chứng sợ bỏ lỡ cơ hội. Trong chứng khoán, đây là tâm lý thôi thúc nhà đầu tư mua đuổi khi thấy giá cổ phiếu đang tăng mạnh. ↩
-
Data Literacy: Hiểu biết về dữ liệu (Thành thạo dữ liệu). Khả năng đọc, hiểu, sáng tạo và truyền đạt thông tin dưới dạng dữ liệu như một ngôn ngữ. ↩
-
Phe chủ động (Buy Up - BU / Sell Down - SD): Lệnh Buy Up (Mua chủ động) là lệnh do nhà đầu tư thực hiện chủ động mua lên so với giá hiện tại của cổ phiếu. Lệnh Sell Down (Bán chủ động) là lệnh do nhà đầu tư thực hiện chủ động bán dưới giá hiện tại của cổ phiếu. Thống kê khối lượng giao dịch theo lệnh BU – SD giúp nhà đầu tư có thể sử dụng để đánh giá tương quan giữa cung và cầu trên giao dịch thực tế. Kết hợp với diễn biến giá, chỉ số BU/SD có thể giúp nhà đầu tư nhận biết được động thái của các nhà đầu tư lớn. ↩
-
OHLCV: Viết tắt của Open (Giá mở cửa), High (Giá cao nhất), Low (Giá thấp nhất), Close (Giá đóng cửa), Volume (Khối lượng giao dịch). Đây là 5 thông số cơ bản tạo nên một cây nến trên biểu đồ phân tích kỹ thuật. ↩ ↩2
-
Loại bỏ trùng lặp (Deduplicate): Hành động xóa bỏ các bản ghi giống hệt nhau trong một tập dữ liệu nhằm làm sạch dữ liệu. ↩
-
Lệnh thị trường (MP - Market Price): Lệnh mua/bán chứng khoán tại mức giá bán thấp nhất/giá mua cao nhất hiện có trên thị trường, chấp nhận khớp ở bất kỳ giá nào để được giao dịch ngay lập tức. ↩
-
Lấy mẫu (Resampling): Kỹ thuật trong phân tích dữ liệu chuỗi thời gian nhằm chuyển đổi dữ liệu từ tần suất này sang tần suất khác (ví dụ: gộp dữ liệu từng giây thành dữ liệu 1 phút). ↩
-
Pandas: Thư viện mã nguồn mở vô cùng phổ biến trong ngôn ngữ Python, chuyên dùng để thao tác, xử lý và phân tích dữ liệu dạng bảng. ↩
-
Bảng dữ liệu (DataFrame): Cấu trúc dữ liệu 2 chiều (gồm hàng và cột) tương tự như bảng tính Excel, là cấu trúc dữ liệu cốt lõi của thư viện Pandas. ↩
-
Góc nhìn sâu sắc (Insights): Sự thấu hiểu sâu sắc bản chất của một vấn đề dựa trên việc phân tích dữ liệu, từ đó giúp đưa ra các quyết định hành động cụ thể. ↩
-
Bản đồ nhiệt (Volume Profile / Footprint): Các dạng biểu đồ nâng cao hiển thị khối lượng giao dịch được phân bổ theo từng mức giá (thay vì theo thời gian như biểu đồ nến thông thường), giúp xác định các vùng hỗ trợ/kháng cự mạnh dựa trên cung cầu thực tế. ↩
-
Phân nhóm dữ liệu (Ví dụ:
pandas.cut): Kỹ thuật phân chia dữ liệu liên tục thành các khoảng (bin) rời rạc. Trong Python,pandas.cutlà một hàm phổ biến để tự động gắn nhãn (label) cho dữ liệu dựa trên các mốc giá trị (threshold) do người dùng định nghĩa. ↩
Bình luận