
Chuẩn Hóa Dữ Liệu Chứng Khoán Khi Vibe Coding Để Tránh Lỗi
Mục lục
Khi phát triển các ứng dụng phân tích dữ liệu chứng khoán bằng Python và AI vibe coding, thao tác thường gặp là anh chị em yêu cầu AI tính toán các chỉ báo kỹ thuật như RSI, MACD hay lọc cổ phiếu. Ở những bước thử nghiệm đầu tiên, mã nguồn thường chạy rất trơn tru.
Tuy nhiên, vấn đề sẽ phát sinh khi bạn bắt đầu tích hợp dữ liệu từ nhiều nguồn khác nhau. Ví dụ: bạn vừa truy xuất dữ liệu OHLCV qua thư viện Vnstock, vừa gọi trực tiếp dữ liệu từ các API chứng khoán1 như Fast Connect Data. Về bản chất, tất cả nguồn đều trả về dữ liệu giao dịch của cùng một mã cổ phiếu, nhưng đặc tính kỹ thuật lại có sự khác biệt lớn. Ví dụ cụ thể khi so sánh dữ liệu từ nguồn API thô so với thư viện Vnstock:
- Tên trường dữ liệu: Các API thô thường dùng các tên trường viết hoa chữ đầu như
TradingDate,Open,Close, trong khi thư viện Vnstock đã chuẩn hóa về các tên cột viết thường nhưtime,open,close.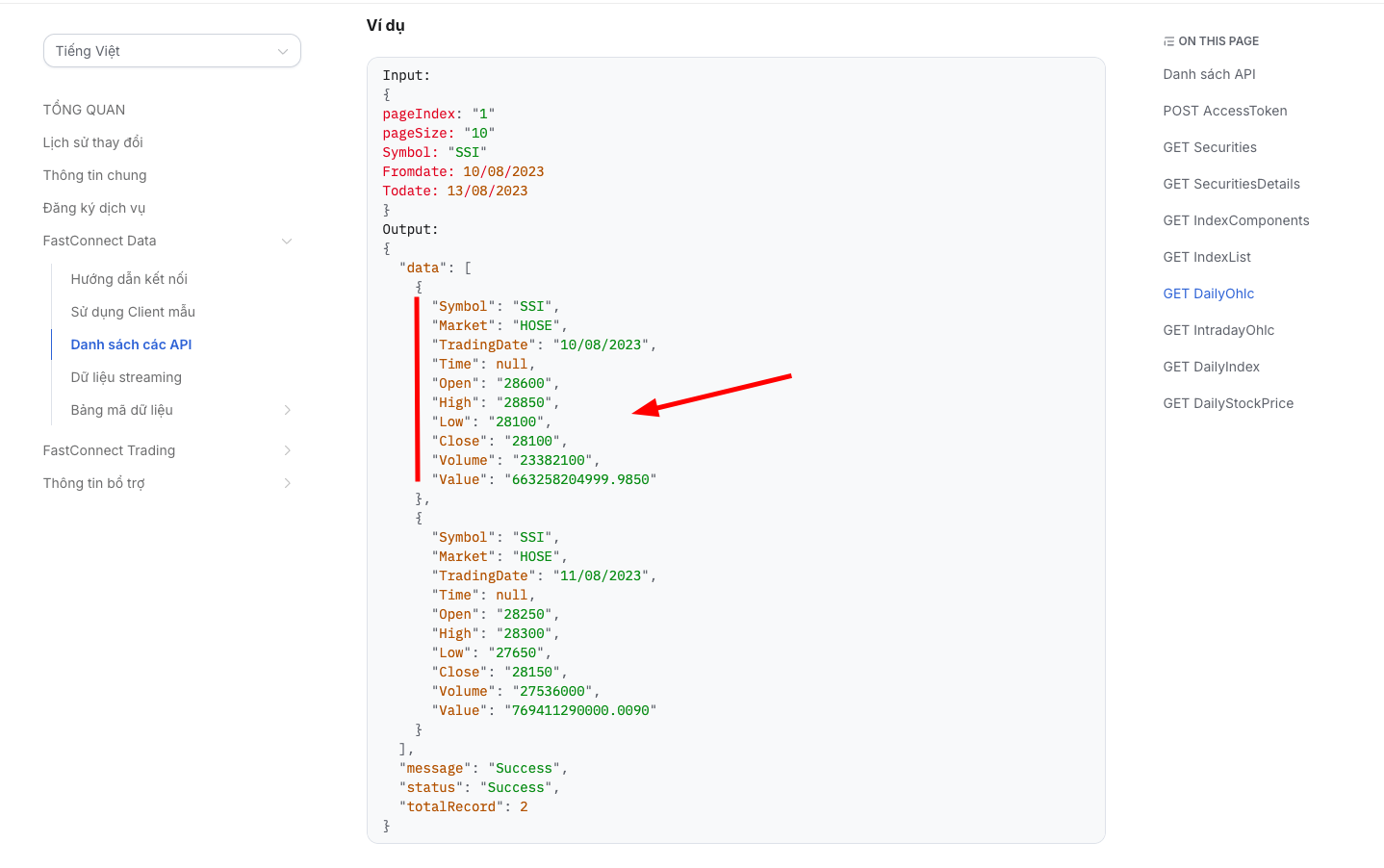 Hình 1: Cấu trúc dữ liệu mẫu trong tài liệu của dịch vụ Fast Connect Data
Hình 1: Cấu trúc dữ liệu mẫu trong tài liệu của dịch vụ Fast Connect Data
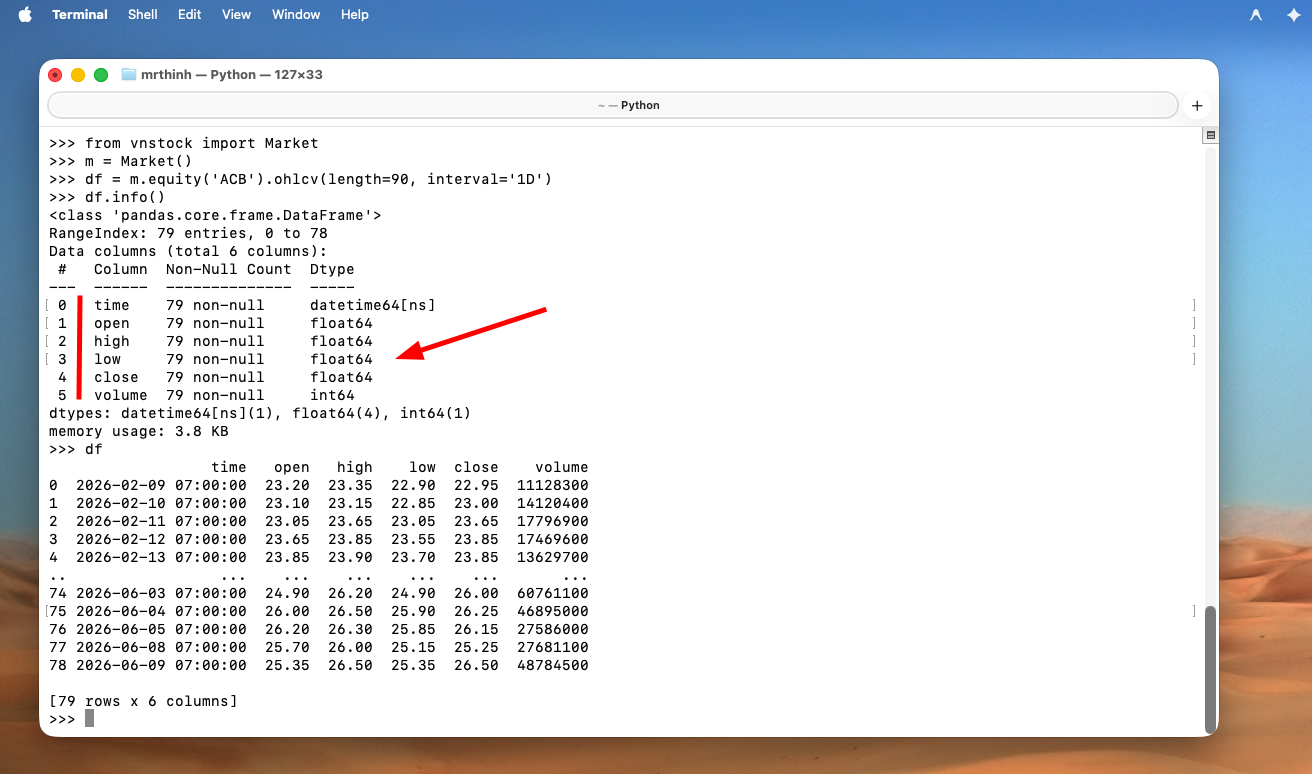 Hình 2: Cấu trúc dữ liệu OHLCV từ Vnstock
Hình 2: Cấu trúc dữ liệu OHLCV từ Vnstock
- Định dạng giá trị: Dữ liệu số từ API thô thường trả về dạng chuỗi chứa số nguyên2 với đơn vị tính là đồng. Ngược lại, Vnstock trả về số thực (
float) cho giá (đã được quy đổi sang đơn vị nghìn đồng3) và số nguyên (int) cho khối lượng. - Cấu trúc cột: Để tối ưu hiệu năng truyền tải, Vnstock khi truy vấn cho một mã cụ thể thường loại bỏ cột mã cổ phiếu4, trong khi dữ liệu từ API chứng khoán thô lại chứa cả thông tin mã cổ phiếu lẫn thông tin sàn giao dịch5.
Nếu thiếu bước tiền xử lý để chuẩn hóa định dạng từ các nguồn khác nhau về một cấu trúc tiêu chuẩn như OHLCV6, thuật toán của bạn sẽ bị phụ thuộc vào một nguồn dữ liệu duy nhất. Khi cấu trúc này thay đổi hoặc gặp sự cố, hệ thống sẽ báo lỗi KeyError7 hoặc TypeError8. Lúc này, bạn dễ gặp tình trạng "sửa lỗi vòng lặp" với AI: nhờ AI sửa để chạy được với nguồn mới thì lại làm hỏng logic của nguồn cũ.
Để giải quyết vấn đề này, bạn nên tách biệt phần kết nối dữ liệu khỏi thuật toán thông qua bước Chuẩn hóa dữ liệu9 trong luồng xử lý dữ liệu10. Việc tiền xử lý giúp đảm bảo mọi tập dữ liệu đều đồng nhất trước khi đưa vào tính toán.
Hình 3: Mô hình Adapter chuẩn hóa dữ liệu chứng khoán từ các nguồn API thô về DataFrame chuẩn.
Tư duy Vibe Coding: Thiết kế bộ chuyển đổi
Thay vì viết các đoạn code chắp vá cho từng API, cách tiếp cận hiệu quả khi vibe coding là yêu cầu AI thiết kế một bộ chuyển đổi - Adapter11 để đưa mọi định dạng đầu vào về một cấu trúc dữ liệu chuẩn12. Đây là nguyên tắc cốt lõi khi chuẩn hóa dữ liệu chứng khoán.
Khi làm việc với các AI Agent13 bạn hãy cung cấp mô tả chi tiết về cấu trúc dữ liệu thay vì để AI tự suy đoán. Dưới đây là mẫu prompt thực tế để bạn tham khảo:
*"Viết một hàm Python đóng vai trò là bộ chuyển đổi để đồng nhất dữ liệu OHLCV từ hai nguồn khác nhau về một cấu trúc dữ liệu DataFrame chuẩn.
Cấu trúc chuẩn đầu ra mong muốn:
- Các cột:
time(datetime),open,high,low,close(float),volume(int),ticker(string).Thông tin 2 nguồn cấp dữ liệu đầu vào:
- Nguồn 1 (Fast Connect API): Đầu vào là JSON14 thô chứa danh sách các dictionary15 nằm trong khoá
data. Các trường dữ liệu số đều đang ở kiểu chuỗi (ví dụ:"Open": "28600"). Yêu cầu ánh xạ bảng tên:TradingDate->time,Open->open,High->high,Low->low,Close->close,Volume->volume,Symbol->ticker. Chú ý ép kiểu dữ liệu16 từ chuỗi sang số nguyên/số thực tương ứng.- Nguồn 2 (Vnstock): Đầu vào là Pandas DataFrame17 đã chuẩn hoá sẵn cấu trúc cột như yêu cầu chuẩn.
Hãy viết code rõ ràng, có chú thích tiếng Việt từng bước."*
Triển Khai Chuẩn Hoá Dữ Liệu OHLCV
Dưới đây là mã nguồn xử lý dữ liệu python thực tế để chuẩn hóa dữ liệu chứng khoán, được thiết kế dựa trên tư duy Adapter ở trên.
Cấu trúc dữ liệu mẫu từ Fast Connect API
{
"data": [
{
"Symbol": "SSI",
"Market": "HOSE",
"TradingDate": "10/08/2023",
"Time": null,
"Open": "28600",
"High": "28850",
"Low": "28100",
"Close": "28100",
"Volume": "23382100",
"Value": "663258204999.9850"
},
{
"Symbol": "SSI",
"Market": "HOSE",
"TradingDate": "11/08/2023",
"Time": null,
"Open": "28250",
"High": "28300",
"Low": "27650",
"Close": "28150",
"Volume": "27536000",
"Value": "769411290000.0090"
}
],
"message": "Success",
"status": "Success",
"totalRecord": 2
}Hàm Chuẩn Hóa Dữ Liệu Bằng Python
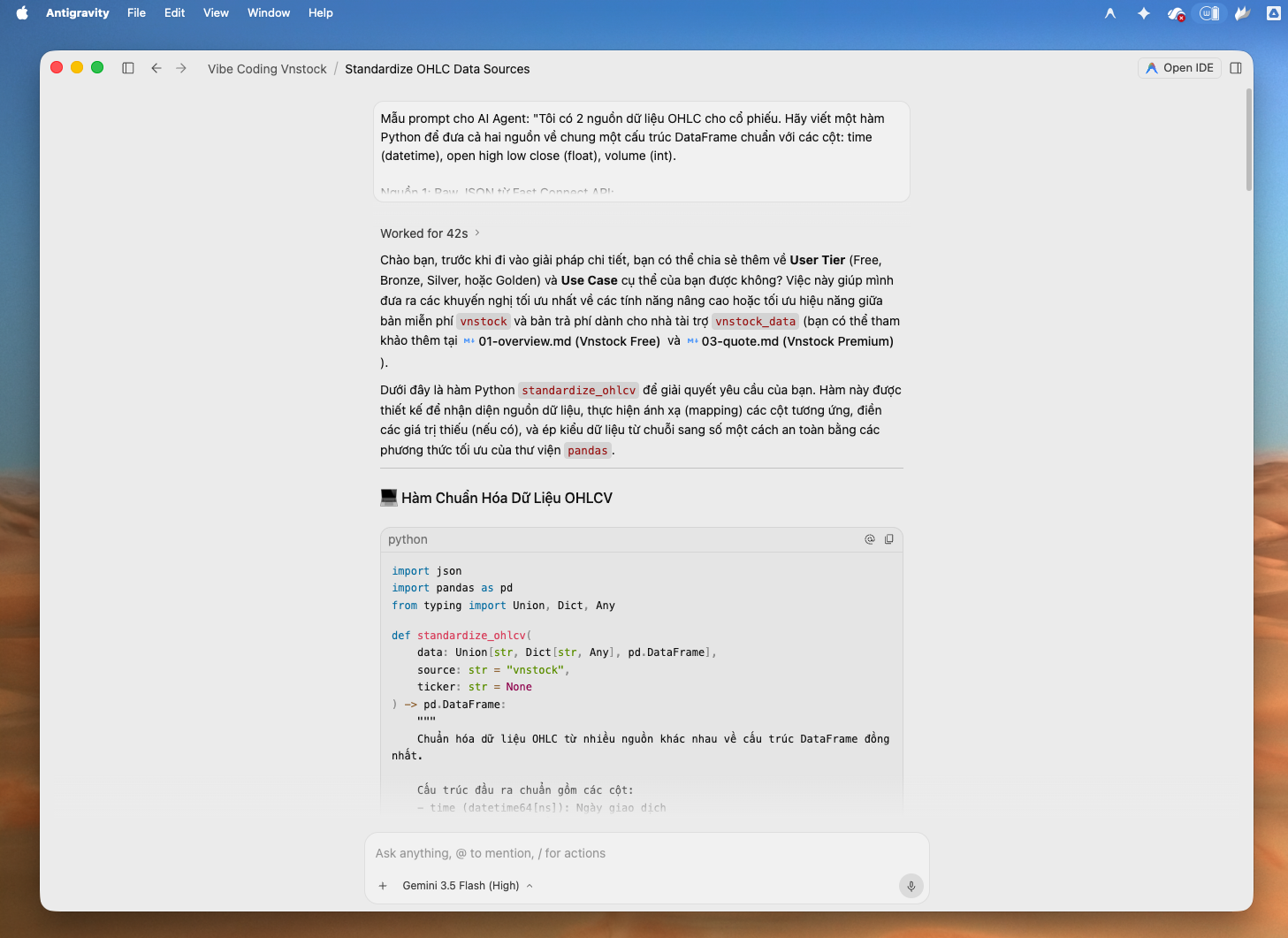 Hình 4: Minh hoạ cách sử dụng Antigravity 2.0 tạo bộ Adapter chuyển đổi nguồn dữ liệu
Hình 4: Minh hoạ cách sử dụng Antigravity 2.0 tạo bộ Adapter chuyển đổi nguồn dữ liệu
Nhờ bước chuẩn hóa dữ liệu chứng khoán này, dù đầu vào là JSON thô từ Fast Connect API với các số đang ở dạng chuỗi, hay DataFrame tinh gọn từ Vnstock, đầu ra trả về vẫn là một DataFrame dạng bảng tính đồng nhất. Thuật toán phân tích kỹ thuật của bạn chỉ cần đọc từ DataFrame chuẩn này mà không sợ xảy ra lỗi định dạng.
Triển Khai Chuẩn Hoá Dữ Liệu Chỉ Số Tài Chính
Một ví dụ thực tế khác là phân tích các chỉ số tài chính. Định dạng báo cáo và chỉ số tài chính của nhóm ngành ngân hàng khác biệt so với doanh nghiệp sản xuất hay dịch vụ18.
Khi bạn sử dụng thư viện vnstock_data để lấy dữ liệu chỉ số qua lệnh:
from vnstock_data import Finance
f = Finance(symbol='ACB', source='VCI')
df_ratios = f.ratio()DataFrame trả về sẽ chứa tới hơn 50 cột chỉ số khác nhau:
# df_ratios.columns
Index(['report_period', 'Ratio TTM Id', 'Ratio Type', 'Outstanding Shares (mil)',
'Market Cap', 'Dividend Yield (%)', 'P/E', 'P/B', 'P/S', ...,
'Net Interest Margin', 'CASA Ratio', 'LDR (%)', 'NPL (%)',
'Cost/Income Ratio', 'CIR', 'ROE (%)', 'ROA (%)', ...], dtype='object')Nếu thuật toán định lượng của bạn muốn tính toán điểm sức khỏe tài chính cho ngân hàng dựa trên các chỉ số cốt lõi, bạn cần lọc và ánh xạ tên cột gốc thành cấu trúc cột nội bộ thống nhất12.
Mẫu prompt thiết kế Adapter cho Chỉ Số nhóm Ngân Hàng:
*"Viết một hàm Python để lọc và chuẩn hóa dữ liệu chỉ số tài chính nhóm ngân hàng từ DataFrame đầu vào (lấy từ thư viện
vnstock_data).Yêu cầu xử lý:
- Lọc dữ liệu: Chỉ giữ lại các cột thông tin cốt lõi.
- Đổi tên cột: Đổi tên các cột giữ lại sang định dạng chuẩn viết thường như sau:
report_period->periodNet Interest Margin->nimCASA Ratio->casaLDR (%)->ldrNPL (%)->nplCost/Income Ratio->cirROE (%)->roeROA (%)->roa- Ép kiểu dữ liệu: Đảm bảo tất cả các cột giá trị số được ép sang kiểu
floatđể phục vụ tính toán.Đầu ra mong muốn là một DataFrame tinh gọn, chỉ chứa các cột đã đổi tên như trên."*
Mã Python Chuẩn Hóa Chỉ Số nhóm Ngân Hàng:
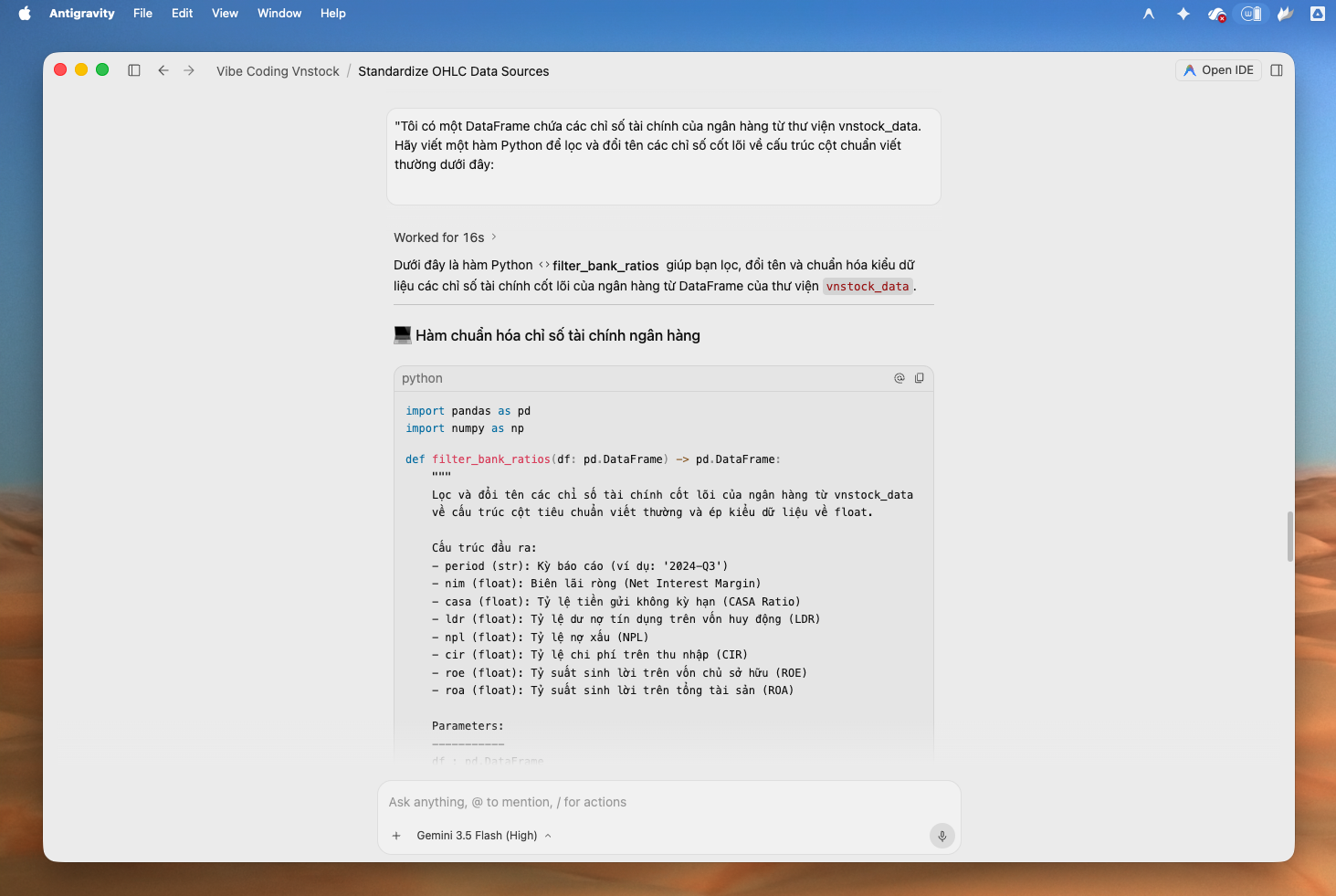 Hình 5: Minh hoạ cách sử dụng Antigravity 2.0 tạo bộ Adapter tạo bộ chuyển đổi dữ liệu chỉ số tài chính
Hình 5: Minh hoạ cách sử dụng Antigravity 2.0 tạo bộ Adapter tạo bộ chuyển đổi dữ liệu chỉ số tài chính
Lời Kết
Khi làm việc với AI trong vibe coding, thay vì yêu cầu AI viết một đoạn code lớn gộp tất cả logic, bạn nên chia nhỏ bài toán theo cấu trúc rõ ràng: kết nối nguồn dữ liệu, chuẩn hóa dữ liệu, và thực thi thuật toán.
Cách tiếp cận này giúp mã nguồn hoạt động ổn định khi các nguồn dữ liệu thay đổi cấu trúc, đồng thời giúp việc giao tiếp với AI Agent13 hiệu quả hơn.
Để bắt đầu, bạn có thể tham khảo thêm bài viết Lựa chọn phiên bản Google Antigravity phù hợp cho Vibe Coding để chọn công cụ phù hợp cho dự án của mình.
Footnotes
-
Các API chứng khoán kết nối dữ liệu thô (raw data): Các cổng kết xuất thông tin giao dịch/giá tự động nổi bật tại Việt Nam như Fast Connect API (dịch vụ của SSI), Lightspeed API (dịch vụ của DNSE), hay iFlash API (dịch vụ của TCBS), cho phép nhà đầu tư truy vấn dữ liệu thô trực tiếp từ hệ thống công ty chứng khoán trước khi đưa vào các thuật toán phân tích. ↩
-
Dữ liệu dạng chuỗi (string) trong API thô: Các API thô thường trả về dữ liệu số dưới dạng chuỗi (ví dụ:
"28600","23382100") nhằm bảo toàn định dạng và độ chính xác của các con số lớn trong chuỗi JSON khi truyền qua môi trường internet. Bạn cần thực hiện ép kiểu số trong Python để có thể tính toán chỉ báo kỹ thuật. ↩ -
Quy đổi đơn vị giá chứng khoán tại Việt Nam: Các bảng giá chứng khoán và bảng điện của các công ty chứng khoán tại Việt Nam thường hiển thị giá cổ phiếu rút gọn bằng cách chia cho 1,000 (ví dụ: giá 28.6 tương đương 28,600 đồng). Thư viện Vnstock tự động đồng bộ giá trị theo đơn vị nghìn đồng để đồng nhất trải nghiệm cho người dùng. ↩
-
Cột mã cổ phiếu (Ticker/Symbol): Mã định danh duy nhất của cổ phiếu niêm yết (ví dụ: FPT, VNM, SSI). Khi thiết kế cơ sở dữ liệu hoặc xử lý nhiều mã cùng lúc, việc thiếu hoặc đặt sai tên cột mã cổ phiếu sẽ dẫn đến các lỗi trộn lẫn dữ liệu giữa các mã khác nhau. ↩
-
Sàn giao dịch chứng khoán (Market/Exchange): Thông tin cho biết cổ phiếu đang niêm yết tại sàn giao dịch nào (ví dụ: HOSE, HNX, UPCoM). Thông tin này thường hữu ích cho việc lọc quy định biên độ dao động giá nhưng có thể lược bỏ nếu bạn chỉ cần phân tích chỉ báo kỹ thuật cơ bản. ↩
-
OHLCV: Định dạng dữ liệu chuỗi thời gian tiêu chuẩn của thị trường tài chính bao gồm Open (Giá mở cửa), High (Giá cao nhất), Low (Giá thấp nhất), Close (Giá đóng cửa), và Volume (Khối lượng giao dịch). ↩
-
KeyError: Một lỗi hệ thống thường gặp trong Python khi truy cập vào một khóa (Key) hoặc tên cột không tồn tại trong Pandas DataFrame. Lỗi này thường xuất hiện khi các nguồn API chứng khoán khác nhau trả về tên cột không đồng nhất. ↩
-
TypeError: Lỗi kiểu dữ liệu trong Python, xảy ra khi thực hiện các phép toán hoặc gọi hàm trên kiểu dữ liệu không tương thích (ví dụ: tính toán chỉ báo kỹ thuật RSI từ giá trị giá dạng chuỗi thay vì dạng số float). ↩
-
Data Standardization (Chuẩn hóa dữ liệu): Quy trình kỹ thuật dữ liệu nhằm đưa các tập dữ liệu có cấu trúc khác nhau về cùng một định dạng chuẩn chung về tên cột, kiểu dữ liệu, múi giờ và đơn vị tính, giúp hệ thống hoạt động ổn định và nhất quán. ↩
-
Data Pipeline (Luồng xử lý dữ liệu): Tập hợp các quy trình tự động hóa nối tiếp nhau, từ khâu thu thập dữ liệu thô, làm sạch, chuẩn hóa cho tới khi nạp vào các mô hình học máy (Machine Learning) hoặc hệ thống phân tích kỹ thuật và giao dịch tự động. ↩
-
Adapter Design Pattern (Mẫu thiết kế bộ chuyển đổi): Một mẫu thiết kế cấu trúc giúp chuyển đổi giao diện của một lớp (class) hoặc cấu trúc dữ liệu thành một giao diện khác mà các hàm tính toán phía sau mong muốn, giúp hệ thống hoạt động linh hoạt, không bị bó buộc vào bất kỳ nguồn cấp dữ liệu cụ thể nào. ↩
-
Standard Schema (Lược đồ chuẩn): Quy chuẩn kỹ thuật xác định danh sách các cột, định dạng và kiểu dữ liệu bắt buộc của một bảng dữ liệu (DataFrame). Giúp lập trình viên viết code logic mà không lo bị ảnh hưởng bởi sự thay đổi của nguồn cấp dữ liệu gốc. ↩ ↩2
-
AI Agent: Tác nhân trí tuệ nhân tạo có khả năng tự chủ thực hiện nhiệm vụ dựa trên các công cụ và hướng dẫn được cung cấp. ↩ ↩2
-
JSON (JavaScript Object Notation): Định dạng trao đổi dữ liệu văn bản phổ biến, dễ đọc ghi bởi cả con người và máy tính. ↩
-
Dictionary: Kiểu dữ liệu tập hợp trình bày theo định dạng từ khoá - giá trị (key-value) trong Python. ↩
-
Type Casting (Ép kiểu dữ liệu): Thao tác lập trình chuyển đổi dữ liệu từ kiểu này sang kiểu khác (ví dụ: sử dụng
pd.to_numerictrong Pandas để đổi chuỗi"28600"thành số thực28600.0để có thể thực hiện tính toán số học). ↩ -
Pandas DataFrame: Cấu trúc dữ liệu dạng bảng hai chiều (hàng và cột) trong Python, hỗ trợ xử lý dữ liệu hiệu năng cao. ↩
-
Đặc thù phân tích tài chính ngành ngân hàng: Khác với các doanh nghiệp sản xuất thông thường, ngân hàng có mô hình kinh doanh tiền tệ đặc thù. Do đó, các nhà phân tích sử dụng các chỉ số chuyên biệt như NIM (Biên tỷ suất lợi nhuận thuần), CASA (Tiền gửi không kỳ hạn), LDR (Tỷ lệ cho vay trên huy động), NPL (Tỷ lệ nợ xấu), và CIR (Tỷ lệ chi phí trên thu nhập) thay cho các chỉ số biên lợi nhuận gộp thông thường. ↩







Bình luận